



Nella regressione logistica, la funzione (.) è definita “logit” e corrisponde al logaritmo dell’odds dell’evento di interesse:
Da queste considerazioni sulla struttura del modello di regressione logistica, si traggono le seguenti conclusioni in relazione al valore assunto dalla funzione logit.
Se Prob(Y) = 0.5, allora l’Odds = 0.5/(1-0.5) = 1; allora logit = log(1) = 0
Se Prob(Y) > 0.5, allora l’Odds > 1; allora logit > 0
Se Prob(Y) < 0.5, allora l’Odds < 1; allora logit < 0
Quando la variabile risposta è costituita da un carattere discreto ordinale, la regressione logistica viene adattata di conseguenza. Infatti, la variabile risposta non assumerà più un valore dicotomico (1 o 0), ma piuttosto n valori arbitrari ordinati, in modo che gli n eventi siano mutualmente esclusivi, così che Y = 1 < 2 < 3 < 4 < … < k. Il modello definisce la probabilità di ciascun evento utilizzando una trasformazione della funzione logit:
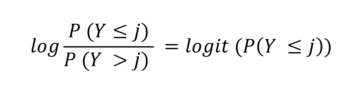
In questo modo, si costruisce un modello per odds proporzionali, che includerà un numero di coefficienti β0 (intercette) pari al numero di livelli k-1 e un numero di coefficienti β pari al numero di confronti. Si prenda ad esempio il caso in cui si voglia testare la soddisfazione dei pazienti rispetto a 3 possibili terapie (1, 2 o 3), in relazione alle quali ogni soggetto ha espresso un giudizio di gradimento (“scarso”, “sufficiente”, “buono”, “ottimo”, “eccellente”). In questo caso, il numero di intercette sarà pari al numero di livelli k-1 = 5-1 = 4. Il numero di confronti, invece, sarà pari al numero di terapie meno uno = 3-1 = 2. In base ai valori di β0 e β sarà possibile definire quale terapia sarà stata maggiormente preferita dai pazienti.
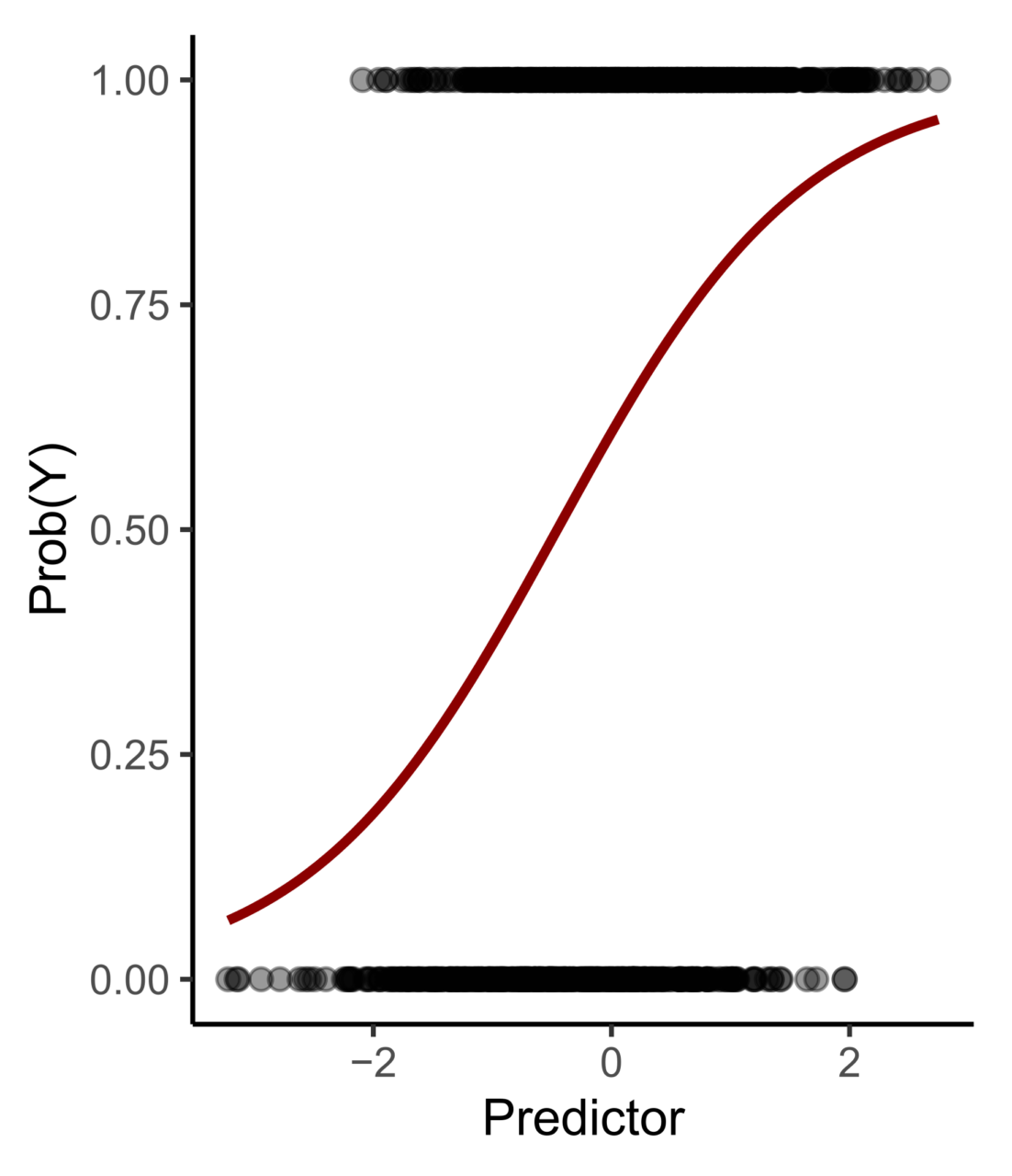
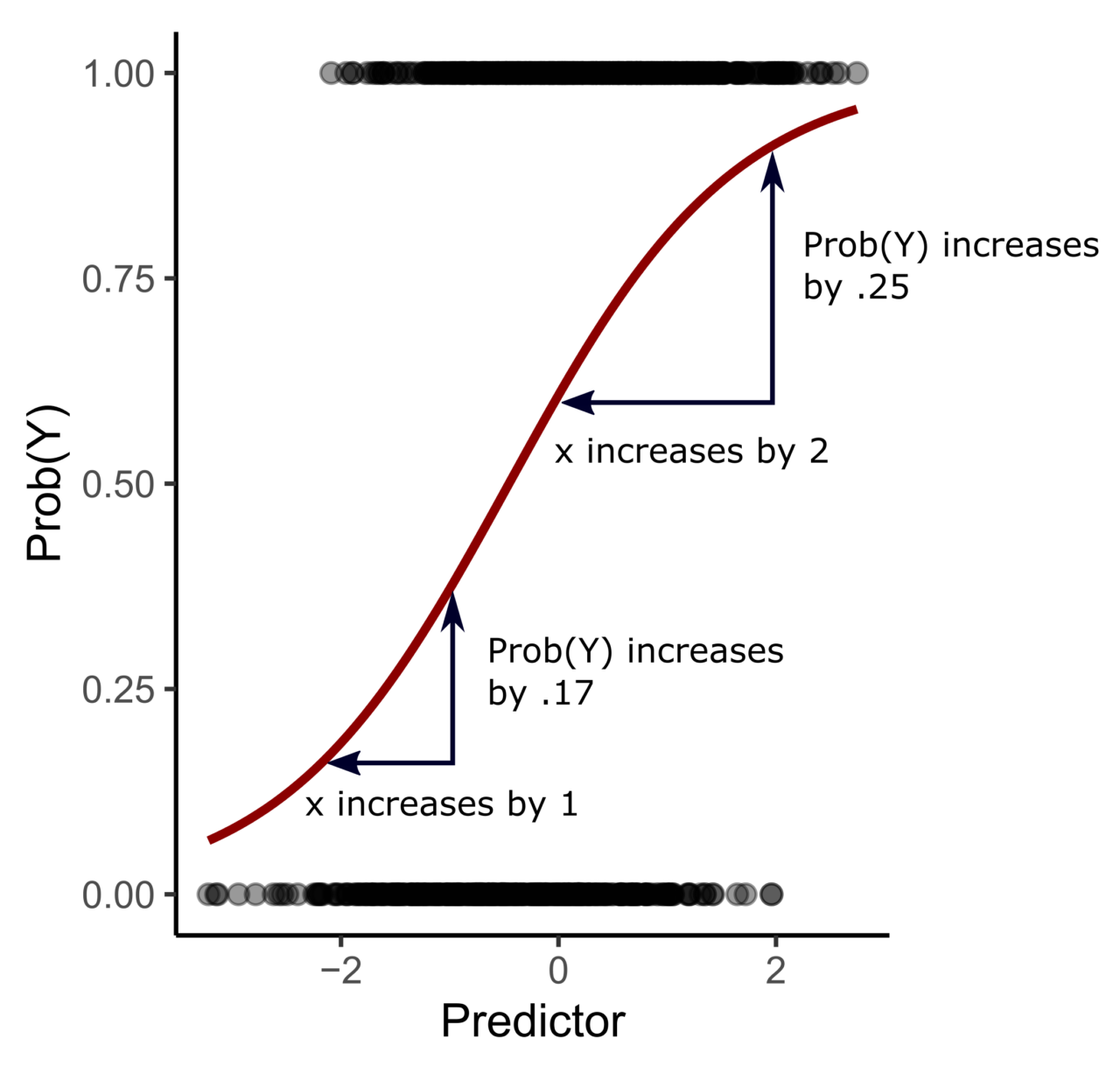
La regressione logistica è un metodo statistico che permette di stimare l’influenza di fattori continui e/o discreti su una variabile categorica, sia essa dicotomica, ordinale o multinomiale. In questo modo, è possibile inferire con quale probabilità Prob(Y) si possa verificare un evento in risposta ai predittori inclusi nel modello.
























